【专注力】专注力提升
专注是脑力劳动者必须掌握的技能,我时常在学习的过程中出现走神、反邹,我将其归功于专注力的缺失,寻找有效的专注力训练方法以及了解专注本身的原理将是一个很好的解决办法。
一、方法一¶
参考视频:为什么我能每天学习10小时
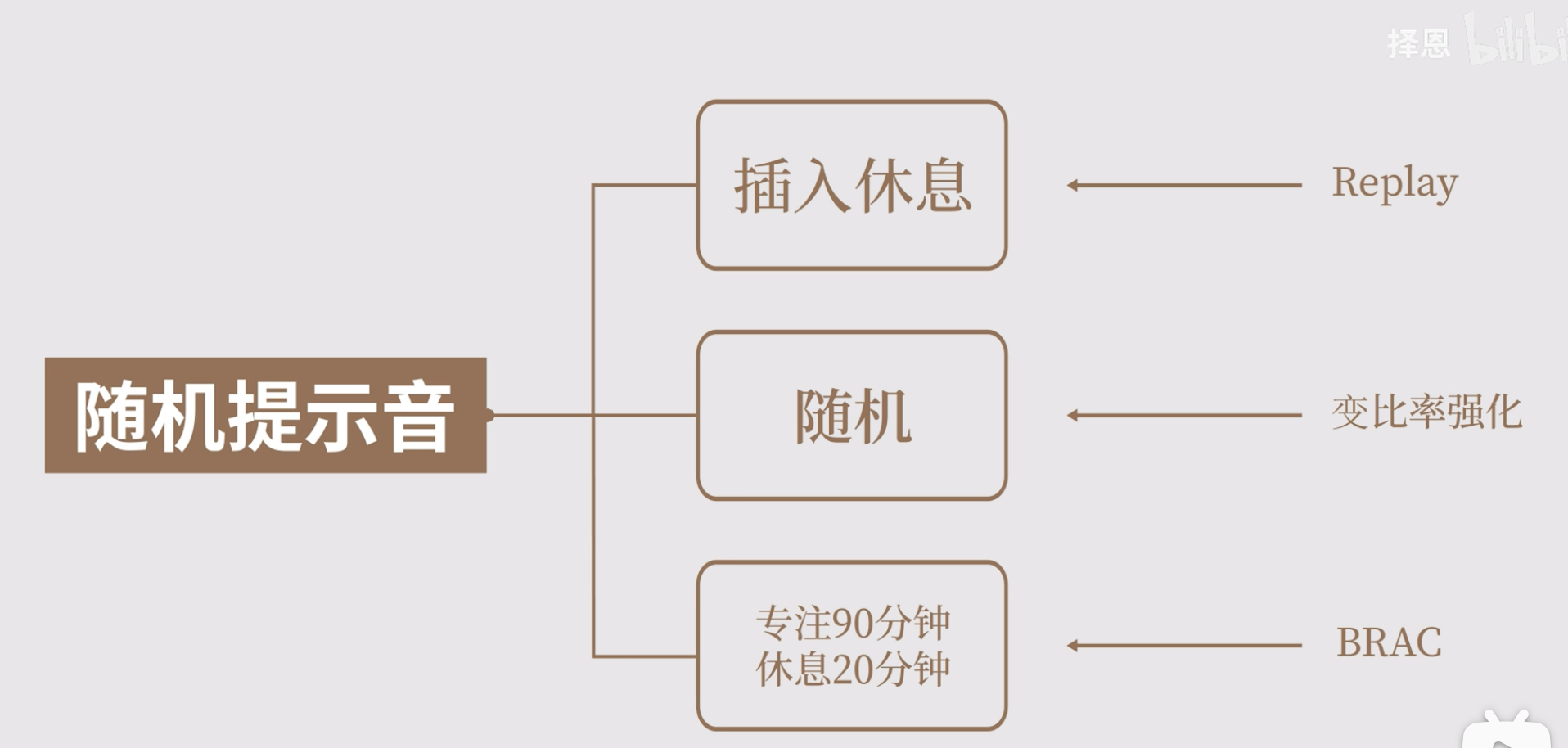
该方法的核心:
- 插入休息
- 原理:神经重放
- 作用:调用被动复习机制
- 随机
- 原理:变比率强化
- 作用:类似抽卡保底机制,大脑知道有保底会一直学下去
- 专注 90 分钟,休息 20 分钟
- 原理:番茄工作法的继承
- 作用:休息
下面来讲讲。
1.1 插入休息¶
首先是插入休息,这里提到了神经重放,大体说的就是人脑在休息时会自动在“后台”复习学过的内容,而且效率极高,甚至能达到学习时的数十倍。
番茄工作法是学 25 分钟休息 5 分钟,而这种方法是在 3~5 分钟内随机地让你休息,每次休息 10 秒钟。
相比于🍅而言,这里的休息频率显著地提高了,几乎极致地利用了神经重放原理。
1.2 变比率强化 - Variable Ratio¶
视频中提到变比率是最强的一种神经强化,类似于游戏中的抽卡保底机制。看来最懂大脑奖励机制的还是游戏策划啊。
出于对强化这一概念的好奇,我特地去搜寻了有关“强化”这一概念的资料。
强化
- 强化(Reinforcement):任何能够增加行为在未来发生概率的后果。
- 正强化(Positive Reinforcement):通过呈现一个愉悦刺激(如奖励、赞美)来增加行为。
- 负强化(Negative Reinforcement):通过移除一个厌恶刺激(如停止噪音、结束工作)来增加行为。
强化程式则决定了何时以及如何 often 行为会得到强化。它主要分为两大类:连续强化和间歇强化。变比率强化属于间歇强化的一种。
变比率强化 - Variable Ratio
- 机制:在平均发生第 N 次行为后给予一次强化,但具体的次数是不固定的、变化的。
- 例子:抽卡手游,老虎机/赌博,你平均拉100次杠杆可能会中一次大奖,但具体哪一次中奖完全未知。可能是下一次,也可能再拉200次也不中。
- 行为模式:会产生极高、稳定且持久的反应率。行为者会“痴迷地”、“不停顿地”做出行为,因为“下一次可能就是奖励”。这也是为什么赌博等机制容易让人上瘾的根本原因。它是最能抵抗“行为消退”(Extinction)的机制,因为行为者很难判断到底是“奖励只是迟到了”还是“奖励真的没有了”。
这里可以看到,变比率强化是真的很强大。看完其行为模式,我不经身上起了一阵鸡皮疙瘩,如果我能将这种行为模式完美地移植到我每天的学习行为上,我不就不用担心启动困难、学习时长等问题了?
同时这也反映了传统番茄工作法的一个缺陷:定比率强化导致的随机性缺失,没有利用到这种随机性。
固定比率强化 - Fixed Ratio, FR
- 机制:在固定发生第 N 次行为后给予一次强化。
- 例子:
- 计件工资:每组装完10个零件(FR-10)获得一次报酬。
- 咖啡店积分卡:每买满10杯咖啡(FR-10)免费赠送一杯。
- 背单词App:每学完20个单词(FR-20)得到一个勋章。
- 行为模式:会产生非常高的反应率,但会在每次强化后有一个短暂的停顿。行为者会“冲刺”以达到目标次数,然后休息一下,再开始下一个“冲刺”。相比VR,它更容易产生倦怠感,且更容易消退(如果奖励突然停止,人们会很快意识到)。
变时距强化 - Variable Interval, VI
- 机制:在平均时间间隔 N 后,第一次做出的正确行为会得到强化。时间间隔是变化的。
- 例子:
- 查看电子邮件/微信消息:平均每半小时可能会收到一封重要邮件(奖励),但具体什么时候来你不知道,所以你只能时不时地去检查(行为)。
- 钓鱼:鱼平均每10分钟可能会上钩一次,但你不知道具体何时,所以你必须保持持续的注意力。
- 老师随堂测验:老师平均一周会进行一次突袭测验(奖励是考得好成绩),但学生不知道具体是哪天,因此他们需要保持日常的复习。
- 行为模式:会产生稳定、中等但持久的反应率。行为者会表现出“持续性的、匀速的”行为,因为奖励可能在“任何时间”出现。反应率不如比率程式高,但非常耐消退。
固定时距强化 - Fixed Interval, FI
- 机制:在一个固定的时间间隔 N 后,第一次做出的正确行为会得到强化。 例子:
- 定时薪水:每周五发薪日(FI-7天),发薪前努力工作,发薪后效率可能降低。
- 期末考试:课程结束时固定有一次考试(奖励是成绩),学生在学期初期学习行为较少,临近考试时行为(学习)急剧增加。
- 行为模式:会产生一种 “扇贝形”反应模式——在强化后(如刚发完工资/考完试)反应率急剧下降,然后随着下一个时间点的临近,反应率又逐渐攀升。这是效率较低的一种模式。
再次看到,番茄钟其实就是一种固定时距的强化模式。每周五发薪水的薪水就是奖励,而番茄工作法中的休息就是奖励。每 25 分钟休息一次本质上就是一种固定发薪水的模式。
当然,番茄工作法采用固定模式更多是为了构建起条件反射。为了让 25 分钟和专注这两件事情关联在一起,不能否认其有效性。
1.3 专注 - 休息¶
这种模式和传统的番茄工作法完全一致,所以我认为这中方法就是对番茄工作法的一种改良。
在传统番茄工作法以工作+休息为一个周期的基本框架下,加入了“抽卡机制”——变比率强化,这种变比率强化的副产物就是所谓的“神经重放”,这两者是同时发生,同时起作用的。
对于强化机制,我们不仅可以将其应用到学习上,更应该警惕生活那些采用强化机制来影响你学习的产品。
总的来说,就这种变时距+变比率的强化模式还是很值得一试的。5 分钟内随机休息保证了休息的平均值,也就是保底——五分钟。同时也保证了变时距+变比率,每次获得休息的时距和概率都会变化,充满不确定性。
遗憾的是,市面上似乎还没有诞生很好的软件来执行,目前该方法停留于理论阶段。番茄 Todo 似乎没有此功能。